![《深度神经网络FPGA设计与实现》[76M]PDF|百度网盘|亲测有效](https://img10.360buyimg.com/pcpubliccms/jfs/t1/454118/16/575/70259/6a23cf94F5079baf1/0914320320bbd23c.jpg "深度神经网络FPGA设计与实现")
深度神经网络FPGA设计与实现 pdf下载
isbn:9787560657431
限时特惠
00:00:00
活动结束后恢复原价
纸质书参考价
¥8
电子版限时价
¥0.00
省 8 元
选择版本
内容简介
本篇主要提供深度神经网络FPGA设计与实现电子书的pdf版本下载,本电子书下载方式为百度网盘方式,点击以上按钮下单完成后即会通过邮件和网页的方式发货,有问题请联系邮箱ebook666@outlook.com
内容简介
《深度神经网络FPGA设计与实现》从深度神经网络和AI芯片研究现状出发,系统地论述了目前深度学习主流开发平台和深度神经网络基于FPGA平台实现加速的开发原理和应用实例。
《深度神经网络FPGA设计与实现》主要包括5部分:第1~2章介绍了深度神经网络的发展,并总结了深度学习主流开发平台和AI芯片的研究现状;第3~6章在对深度神经网络基础层算子、FPGA进行了介绍后,总结了FPGA神经网络开发基础及RTL级开发;第7章分析了基于FPGA实现神经网络加速的实例;第8章介绍了基于OpenCL的FPGA神经网络计算加速开发;第9章分析了前沿神经网络压缩与加速技术。
《深度神经网络FPGA设计与实现》可以为人工智能、计算机科学、信息科学、神经网络加速计算研究者或者从事深度学习、图像处理的相关研究人员提供参考,也可作为相关专业本科生及研究生的教学参考书。
《深度神经网络FPGA设计与实现》主要包括5部分:第1~2章介绍了深度神经网络的发展,并总结了深度学习主流开发平台和AI芯片的研究现状;第3~6章在对深度神经网络基础层算子、FPGA进行了介绍后,总结了FPGA神经网络开发基础及RTL级开发;第7章分析了基于FPGA实现神经网络加速的实例;第8章介绍了基于OpenCL的FPGA神经网络计算加速开发;第9章分析了前沿神经网络压缩与加速技术。
《深度神经网络FPGA设计与实现》可以为人工智能、计算机科学、信息科学、神经网络加速计算研究者或者从事深度学习、图像处理的相关研究人员提供参考,也可作为相关专业本科生及研究生的教学参考书。
作者简介
本书从深度神经网络和AI芯片研究现状出发,系统地论述了目前深度学习主流开发平台和深度神经网络基于FPGA平台实现加速的开发原理和应用实例。全书主要包括5部分:第1~2章介绍了深度神经网络的发展,并总结了深度学习主流开发平台和AI芯片的研究现状;第3~6章在对深度神经网络基础层算子、FPGA进行了介绍后,总结了FPGA神经网络开发基础及RTL级开发;第7章分析了基于FPGA实现神经网络加速的实例;第8章介绍了基于OpenCL的FPGA神经网络计算加速开发;第9章分析了前沿神经网络压缩与加速技术。
本书可以为人工智能、计算机科学、信息科学、神经网络加速计算研究者或者从事深度学习、图像处理的相关研究人员提供参考,也可作为相关专业本科生及研究生的教学参考书。
内页插图

目录
第1章 深度学习及AI芯片
1.1 深度学习研究现状
1.1.1 深度学习的概念
1.1.2 深度学习和神经网络的发展历程
1.1.3 典型的深度神经网络
1.1.4 深度学习的典型应用
1.2 AI芯片研究现状
1.2.1 GPU
1.2.2 半制定FPGA
1.2.3 全定制ASIC
1.2.4 SoC
1.2.5 类脑芯片
第2章 深度学习开发平台
2.1 深度学习平台介绍
2.1.1 TensorFlow
2.1.2 Caffe
2.1.3 Pytorch
2.1.4 MXNet
2.1.5 CNTK
2.1.6 PaddlePaddle
2.1.7 Darknet
2.2 深度学习平台对比
第3章 深度神经网络基础层算子介绍
3.1 卷积算子
3.2 反卷积算子
3.3 池化算子
3.3.1 平均池化算子
3.3.2 最大池化算子
3.4 激活算子
3.5 全连接算子
3.6 Softmax算子
3.7 批标准化算子
3.8 Shortcut算子
第4章 FPGA基本介绍
4.1 FPGA概述
4.1.1 可编程逻辑器件
4.1.2 FPGA的特点
4.1.3 FPGA的体系结构
4.2 FPGA系列及型号选择
4.2.1 FPGA生产厂家
4.2.2 FPGA系列
4.2.3 基于应用的FPGA型号选择
4.3 FPGA性能衡量指标
第5章 FPGA神经网络开发基础
5.1 FPGA开发简介
5.2 FPGA的结构特性与优势
5.3 FPGA深度学习神经网络加速计算的开发过程
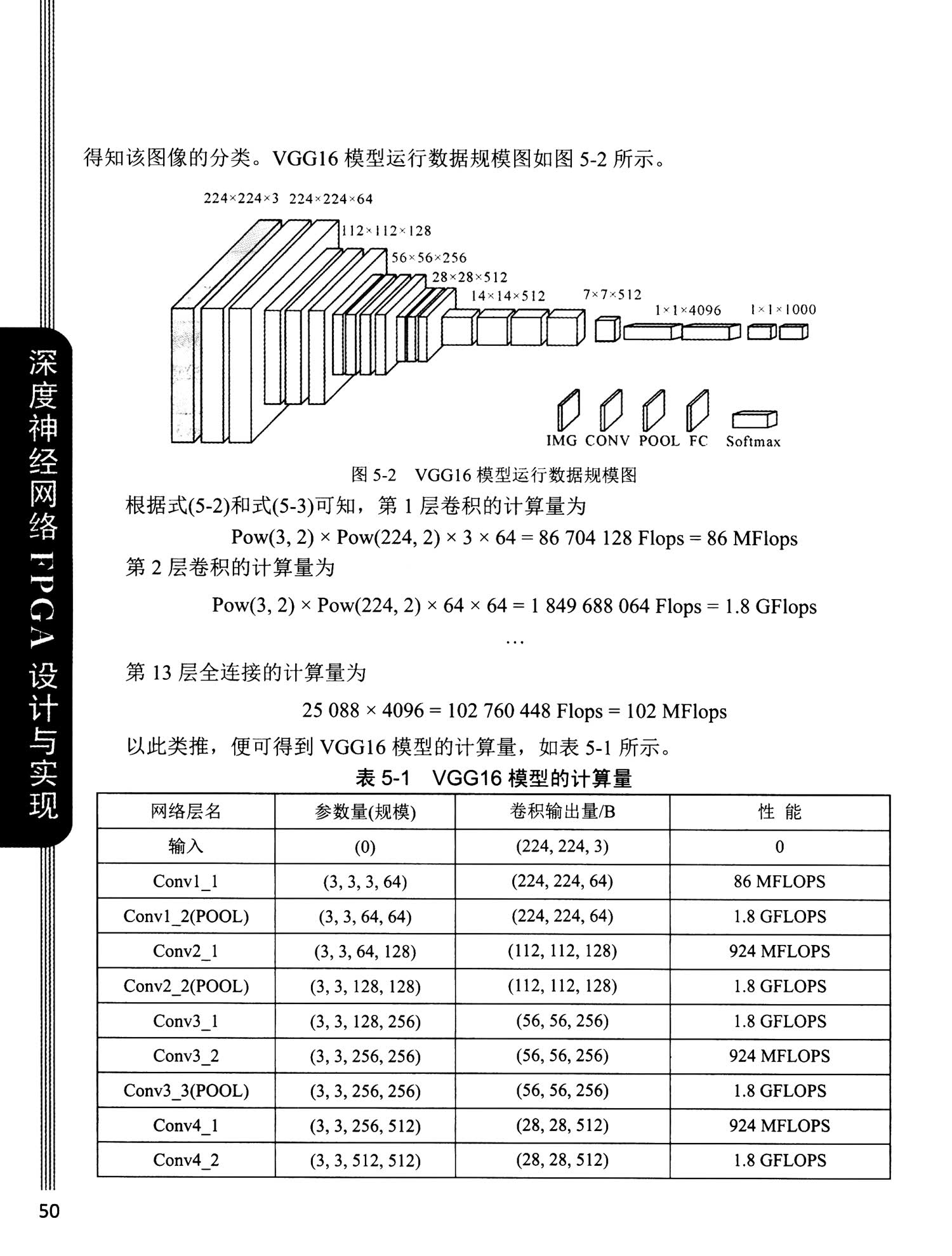
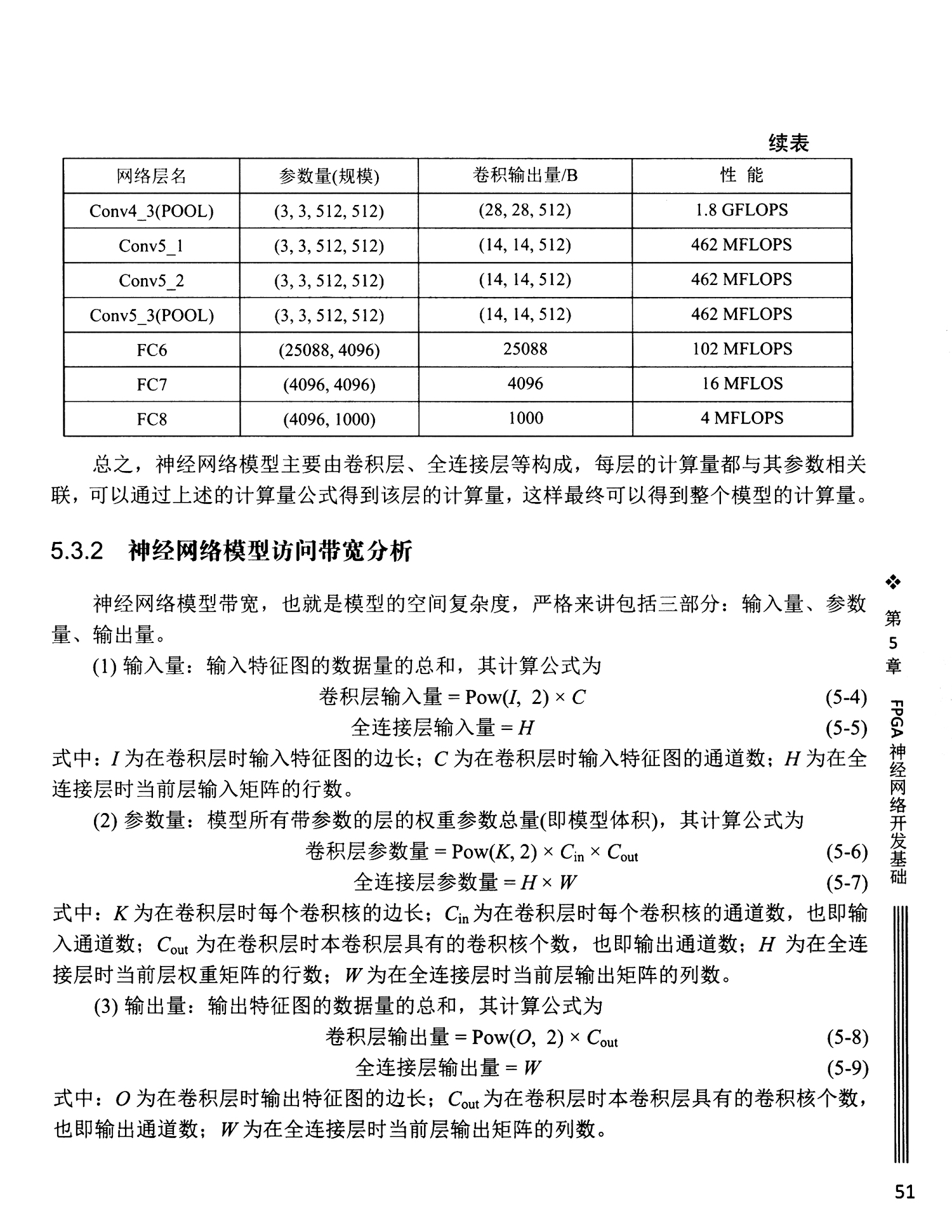
5.3.1 神经网络模型计算量分析
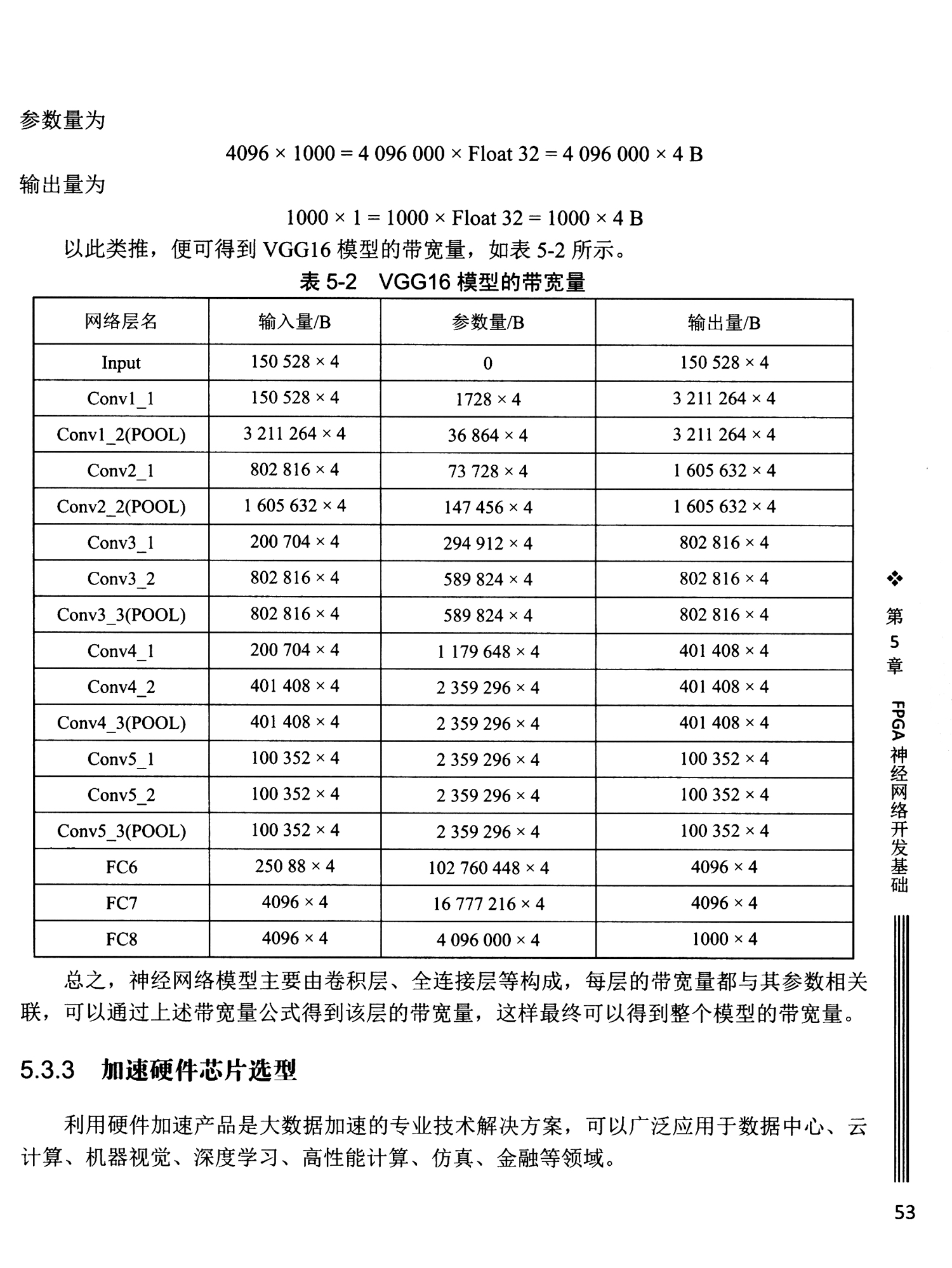
5.3.2 神经网络模型访问带宽分析
5.3.3 加速硬件芯片选型
5.3.4 加速硬件系统设计
5.4 FPGA在深度学习方面的发展
第6章 FPGA神经网络计算的RTL级开发
6.1 搭建开发环境
6.1.1 开发环境的选择
6.1.2 开发环境的搭建
6.2 RTL级开发的优势与劣势
6.3 RTL级开发的基本流程
6.3.1 需求理解
6.3.2 方案评估
6.3.3 芯片理解
6.3.4 详细方案设计
6.3.5 RTL级HDL设计输入
6.3.6 功能仿真
6.3.7 综合优化
6.3.8 布局布线与实现
6.3.9 静态时序分析与优化
6.3.10 芯片编程与调试
6.4 RTL级神经网络加速设计流程
6.5 RTL级神经网络加速仿真
6.6 RTL级神经网络加速时序优化
……
第7章 基于FPGA实现YOLOV2模型计算加速实例分析
第8章 基于OpenCL的FPGA神经网络计算加速开发
第9章 神经网络压缩与加速技术
参考文献
1.1 深度学习研究现状
1.1.1 深度学习的概念
1.1.2 深度学习和神经网络的发展历程
1.1.3 典型的深度神经网络
1.1.4 深度学习的典型应用
1.2 AI芯片研究现状
1.2.1 GPU
1.2.2 半制定FPGA
1.2.3 全定制ASIC
1.2.4 SoC
1.2.5 类脑芯片
第2章 深度学习开发平台
2.1 深度学习平台介绍
2.1.1 TensorFlow
2.1.2 Caffe
2.1.3 Pytorch
2.1.4 MXNet
2.1.5 CNTK
2.1.6 PaddlePaddle
2.1.7 Darknet
2.2 深度学习平台对比
第3章 深度神经网络基础层算子介绍
3.1 卷积算子
3.2 反卷积算子
3.3 池化算子
3.3.1 平均池化算子
3.3.2 最大池化算子
3.4 激活算子
3.5 全连接算子
3.6 Softmax算子
3.7 批标准化算子
3.8 Shortcut算子
第4章 FPGA基本介绍
4.1 FPGA概述
4.1.1 可编程逻辑器件
4.1.2 FPGA的特点
4.1.3 FPGA的体系结构
4.2 FPGA系列及型号选择
4.2.1 FPGA生产厂家
4.2.2 FPGA系列
4.2.3 基于应用的FPGA型号选择
4.3 FPGA性能衡量指标
第5章 FPGA神经网络开发基础
5.1 FPGA开发简介
5.2 FPGA的结构特性与优势
5.3 FPGA深度学习神经网络加速计算的开发过程
5.3.1 神经网络模型计算量分析
5.3.2 神经网络模型访问带宽分析
5.3.3 加速硬件芯片选型
5.3.4 加速硬件系统设计
5.4 FPGA在深度学习方面的发展
第6章 FPGA神经网络计算的RTL级开发
6.1 搭建开发环境
6.1.1 开发环境的选择
6.1.2 开发环境的搭建
6.2 RTL级开发的优势与劣势
6.3 RTL级开发的基本流程
6.3.1 需求理解
6.3.2 方案评估
6.3.3 芯片理解
6.3.4 详细方案设计
6.3.5 RTL级HDL设计输入
6.3.6 功能仿真
6.3.7 综合优化
6.3.8 布局布线与实现
6.3.9 静态时序分析与优化
6.3.10 芯片编程与调试
6.4 RTL级神经网络加速设计流程
6.5 RTL级神经网络加速仿真
6.6 RTL级神经网络加速时序优化
……
第7章 基于FPGA实现YOLOV2模型计算加速实例分析
第8章 基于OpenCL的FPGA神经网络计算加速开发
第9章 神经网络压缩与加速技术
参考文献
前言/序言
近几年来,随着计算机技术的发展以及硬件设备计算能力的提高,人工智能技术得到了飞速发展,神经网络也由原来的浅层发展至深层,由此引出深度学习的概念。深度学习在图像处理、语音识别、机器控制等领域取得了巨大的突破,很多公司都希望在人工智能领域有所成就,试图抓住先机,占领应用市场,因此相关专业人才供不应求。研究者一般使用多个GPU(Graphics Processing Unit,图形处理器)或者计算机集群进行深层复杂模型的研究与探索,从而解决更加复杂的问题,但却忽略了能量消耗与计算资源的限制因素。虽然很多算法在GPU加速条件下可以实现不错的效果,但是距离工业界的实际要求还有很大的差距,很多复杂模型无法部署在小型设备上或者计算实时性无法满足应用需求,这也是困扰众多工程师的主要难题。
现场可编程门阵列(Field Programmable Gate Array,FPGA)可以通过硬件描述语言(Verilog或VHDL)或C/C++/Open CL进行编程,它具有提供原始计算能力、设计灵活、安全可靠、高效率和低功耗的优势。目前一些公司和研究机构把深度学习的模型迁移到FPGA上,以满足工业和特殊领域的使用需求。FPGA在深度学习中的研究大致可以分为对特定的应用程序进行加速、对特定的算法进行加速、对算法的公共特性进行加速,以及带有硬件模板的通用加速器框架设计。在芯片需求还未形成规模、算法需要不断改进的情况下,FPGA大大降低了从算法到芯片电路的调试成本,也是实现半定制人工智能芯片的最佳选择之一。
现场可编程门阵列(Field Programmable Gate Array,FPGA)可以通过硬件描述语言(Verilog或VHDL)或C/C++/Open CL进行编程,它具有提供原始计算能力、设计灵活、安全可靠、高效率和低功耗的优势。目前一些公司和研究机构把深度学习的模型迁移到FPGA上,以满足工业和特殊领域的使用需求。FPGA在深度学习中的研究大致可以分为对特定的应用程序进行加速、对特定的算法进行加速、对算法的公共特性进行加速,以及带有硬件模板的通用加速器框架设计。在芯片需求还未形成规模、算法需要不断改进的情况下,FPGA大大降低了从算法到芯片电路的调试成本,也是实现半定制人工智能芯片的最佳选择之一。
![《从CPU到SoC的设计与实现 :基于高云云源软件和FPGA硬件平台》[36M]PDF|百度网盘|亲测有效](https://img10.360buyimg.com/pcpubliccms/jfs/t1/202653/20/39712/65653/65fa5a99F6500310e/1ccb95c8d61e1ad8.jpg)
![《RISC-V处理器与片上系统设计----基于FPGA与云平台的实验教程》[56M]PDF|百度网盘|亲测有效](https://img10.360buyimg.com/pcpubliccms/jfs/t1/449815/20/5068/78990/6a23cd66Fdd0cf05c/0914320320e98371.jpg)
![《FPGA现代数字系统设计教程——基于Xilinx可编程逻辑器件与Vivado平台(高等学校电子信》[35M]PDF|百度网盘|亲测有效](https://img10.360buyimg.com/pcpubliccms/jfs/t1/446139/17/7378/37213/6a1ebe59F76d3e7d7/0914320320f9e9b3.jpg)
![《Verilog HDL与FPGA数字系统设计 第2版》[96M]PDF|百度网盘|亲测有效](https://img10.360buyimg.com/pcpubliccms/jfs/t1/447846/38/7228/64907/6a23d211F238a97fa/09143203209b0341.jpg)